Only patients that have clinical records are included in this table (patients without any clinical records – no records in any table – are scrubbed prior to release of the national database).
While there is a field for ethnicity and occupation – this data is largely unpopulated, even in the orig fields.
The active status indicates whether a patient is active, inactive, or deceased. This field reflects the status of the patient at the time of the data extraction. Not all patients have a status – it can be dependent on the EMR and the jurisdiction.
A calculated start date has been created to provide researchers with the last record of activity for a patient (the last observed record date in any CPCSSN table). This date can be used to determine a patient’s active status.
Date variables: use Start Date.
EXAM
Eight exam types are coded. Also available, but not coded is Eye Exam (in the orig data only).
If an adult patient has a height and weight then CPCSSN processing will calculate a BMI using the weight and the last recorded height.
Date variables: use Date Created.
FAMILY HISTORY
There is a wealth of data within the orig text – but only about a third of it is coded to calc field.
Some effort has been made to code the data in terms of relationship degree.
To truly get any value from this table would recommend requesting orig field.
Date variables: use Date Created.
GROUP INFO
Largely empty.
For some networks, it does provide some information on team-based care (i.e which providers are operating together in a team).
HEALTH CONDITION
The diagnoses within this table are not as well coded as the billing and encounter diagnosis tables – only 45% of text and codes are processed to calculated fields.
Date variables: Date of Onset is not well populated. However, use this date first, and if missing then use Date Created.
LAB
CPCSSN processing tools only clean and code 53 labs.
Some networks submit all the lab data found within the EMR – so you can find other labs (not coded) in the orig field. However, other networks may only submit the labs that are coded.
For the labs that are coded the lab results and metrics are well-coded into standardized units.
Date variables: use Performed Date, otherwise use Date Created if missing.
MEDICAL PROCEDURE
Contains 3.5 million records.
All uncoded data.
To view the medical procedures you will need to request the name_orig.
Date variables: use Performed Date, otherwise use Date Created is missing.
MEDICATION
All meds are coded to an ATC code.
Significant work has been done to clean up the data in this table, but more work needs to be done to provide better details about the prescriptions (dose, frequency, strength).
The information about dose, frequency, and strength is all there – but it isn’t always parsed into the right fields – so one of the orig fields may contain all the prescription details – parsing and standardizing need to be improved to make this more usable data.
This table easily allows a researcher to determine if a patient has been prescribed a medication.
If a researcher wants more details – duration, dosage, strength, refilles, then would recommend requesting the orig fields (including Name_orig) so the information can be parsed out.
Date variables: use Start Date, if missing use Date Created.
DISEASE CASE INDICATOR
This table provides information on a patient’s classification according to the CPCSSN disease case algorithms.
This table is useful for understanding what criteria were met for the patient’s classification to a CPCSSN disease case.
ENCOUNTER
This table is useful to determine if a patient had a visit/encounter.
The white paper that details how to define a denominator in the CPCSSN database recommends using this table as one of the main tables to determine an active patient population.
It is not recommended that this table be used (via the encounter_ID) to link the records within other tables to determine what happened within one encounter.
In theory, this is possible for some of the EMRs from which we extract data. However, for most of the EMRs, the records within the EMR are not linked together via an encounter_ID.
As such, it is not recommended that you use the encounter_ID to link different data pieces together into one encounter (use dates instead).
The most useful information within this table is the date (encounter date, or date created if missing).
This table has information on the patient’s reason for visiting the primary care provider – often the information provided to the receptionist or administrative person when the appointment was made. However, this data is not cleaned and standardized, so if you want to be able to mine through that information you will need to request the reason_orig field.
Date variables: use Encounter Date (100% populated).
ENCOUNTER DIAGNOSIS
This table is often used in conjunction with the billing table to evaluate diagnoses and symptoms and classify a patient’s disease (health condition status).
For some EMR products from some jurisdictions, this information may be a duplication of what is in the billing table; for other EMR products from other jurisdictions, this information is supplemental to what is in the billing table.
Not all diseases and conditions are coded – only 75% of the code and text is coded.
Date variables: use Date Created.
DISEASE CASE
This table contains information about whether a patient meets the algorithm for one of the validated case definitions implemented within the CPCSSN database (hyperlink)
It is important to know that some of the algorithms have multiple versions – ie an algorithm that has been adjusted to increase sensitivity, or an algorithm that has been adjusted to increase specificity – this is important to think about as what type of study you are doing may determine the type of algorithm you want to use to classify a patient as having a specific disease
Only one version of the case definitions (the agreed upon standard) is provided in this table – this means that there is only one record per patient per disease.
If your study requires an alternate version of a case definition, please make this request when submitting your DAR.
DEPRIVATION
A deprivation record is only available for patients who have a valid postal code (recorded within the EMR and submitted to the central CPCSSN repository).
This table provides one measure of vulnerability indicator – the Pampalon index (link to Pampalon publication).
This is a neighborhood-level measure that uses the postal code to map to a dissemination area (DA), which is what the census data is linked to.
The Pampalon indicator provides a material index and a social index. Each index is a quintile. A patient who lives in a certain postal code has a probability of being in a certain quintile.
Since the mapping is not one-to-one between DAs and postal codes, it requires us to use probabilistic sampling and to consider the possibility of a single postal code mapping onto different SES levels (whether it be income quintiles or deprivation indices).
Within this table, you will see the probability distribution for each index (material and social) for each patient. There are several ways you can work with this:
1) Weighted average: For each patient take the weighted average. Essentially the probabilities within each quintile of the deprivation index will generate a number within the range of 1 to 5. This will transform the ordinal variable (1,2,3,4,5) onto a somewhat continuous scale (e.g., patient with 1.36 deprivation index).
2) Random assignment: Group patients according to their probability distribution and do a random assignment of patients to a quintile, by group. You will need to do the random assignment multiple times to get measures of variability. By creating multiple copies of the same data file through probabilistic sampling; and via multiple imputation methods (or its bootstrap analogues) should, on average, provide an estimate that closely resembles the underlying population-level quantity. Sampling variability will be high with small samples, and thus it can lead to estimation with greater variability. In contrast, sampling variability will be less with bigger samples.
BILLING
This table is one of the most useful tables for determining patient diagnoses and/or reasons for a primary care encounter.
Not all diseases and conditions are coded – only 75% of the code and text is coded to a calculated field.
Diagnostic codes and text are standardized to ICD-9 ontology. It should be noted that, in some provinces (namely Ontario), only three-digit ICD-9 codes are used (no decimal places) which limits the specificity of the code. Keep this in mind when searching for ICD-9 codes.
Patients may have more then one record for a single encounter if the provider billed for multiple services – however, these multiple records for a single encounter will only be present in the database if the services/diagnostic codes were input as separate records. If a provider put multiple codes into one record or field (which happens often) CPCSSN only takes the first code it encounters in the orig field and that is what populates the calculated field.
Another thing to note about how the code_calc field is derived is that the CPCSSN processing tools will first take the original code (code_orig) to populate the code_calc field, and if empty the tool will then look at the text (name_orig) to derive a code_calc. Not all text strings are recognized by the CPCSSN tools – in these instances the code_calc field will be empty.
Further work is needed to understand how often the name_orig and the code_orig align.
Date variables: use Service Date, but if missing use Date Created.
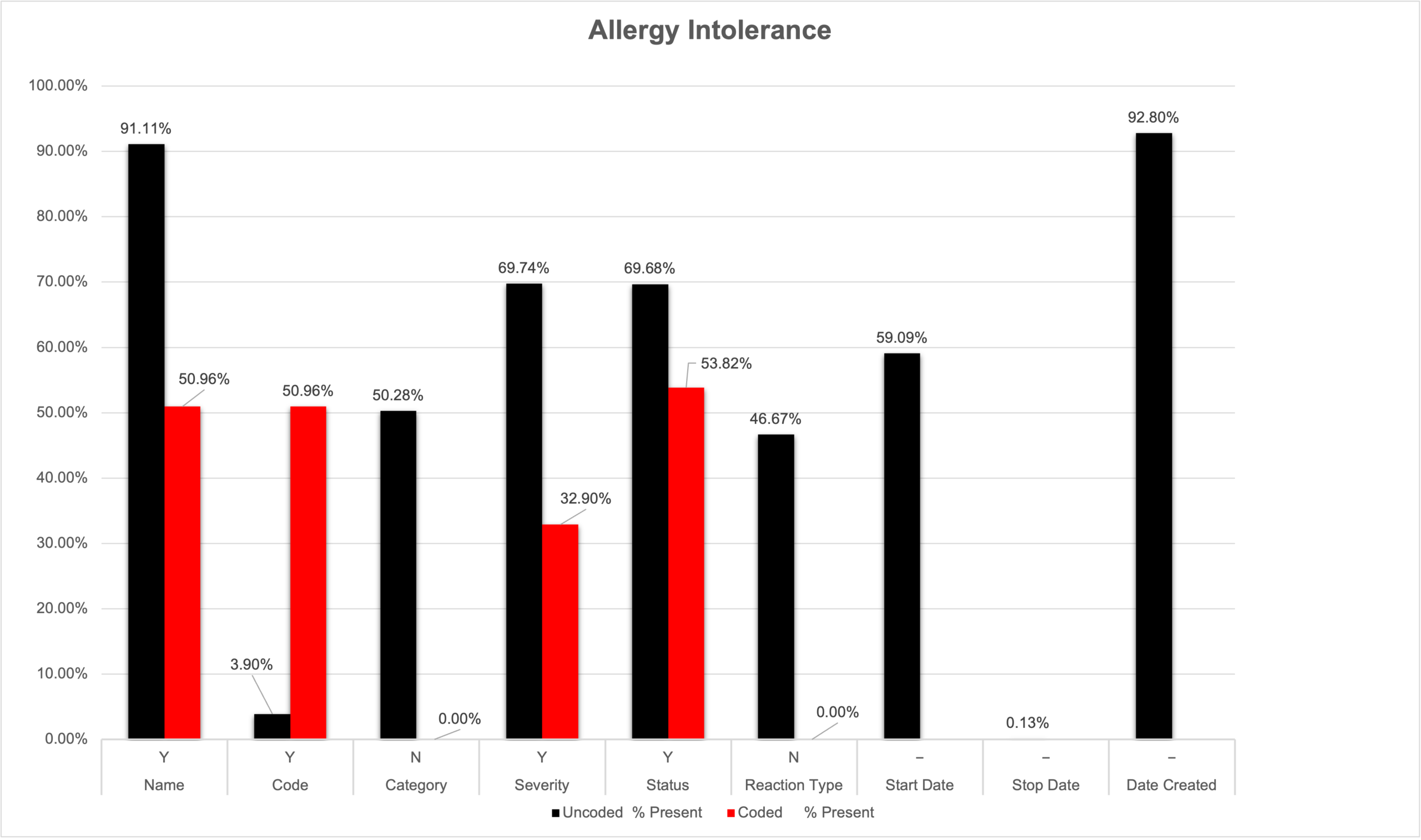
ALLERGY INTOLERANCE
This table contains records on a patient’s allergies or intolerances (drug, food, environmental, animals).
This table is useful for determining documented drug allergies but needs more coding and cleaning to be useful for other types of allergies or intolerances.
Only drug allergies have been coded (to ATC ontology), other types of allergy records (ex. ‘cats’, ‘wasp sting’, ‘no known allergies’) are not coded and the calc field is empty.
The usefulness of this table is limited without orig fields.
Date variables: use Start Date, but if missing use Date Created.